Projects

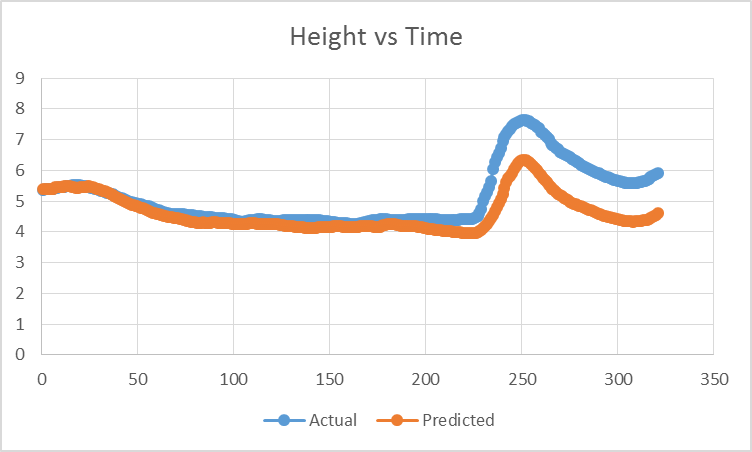
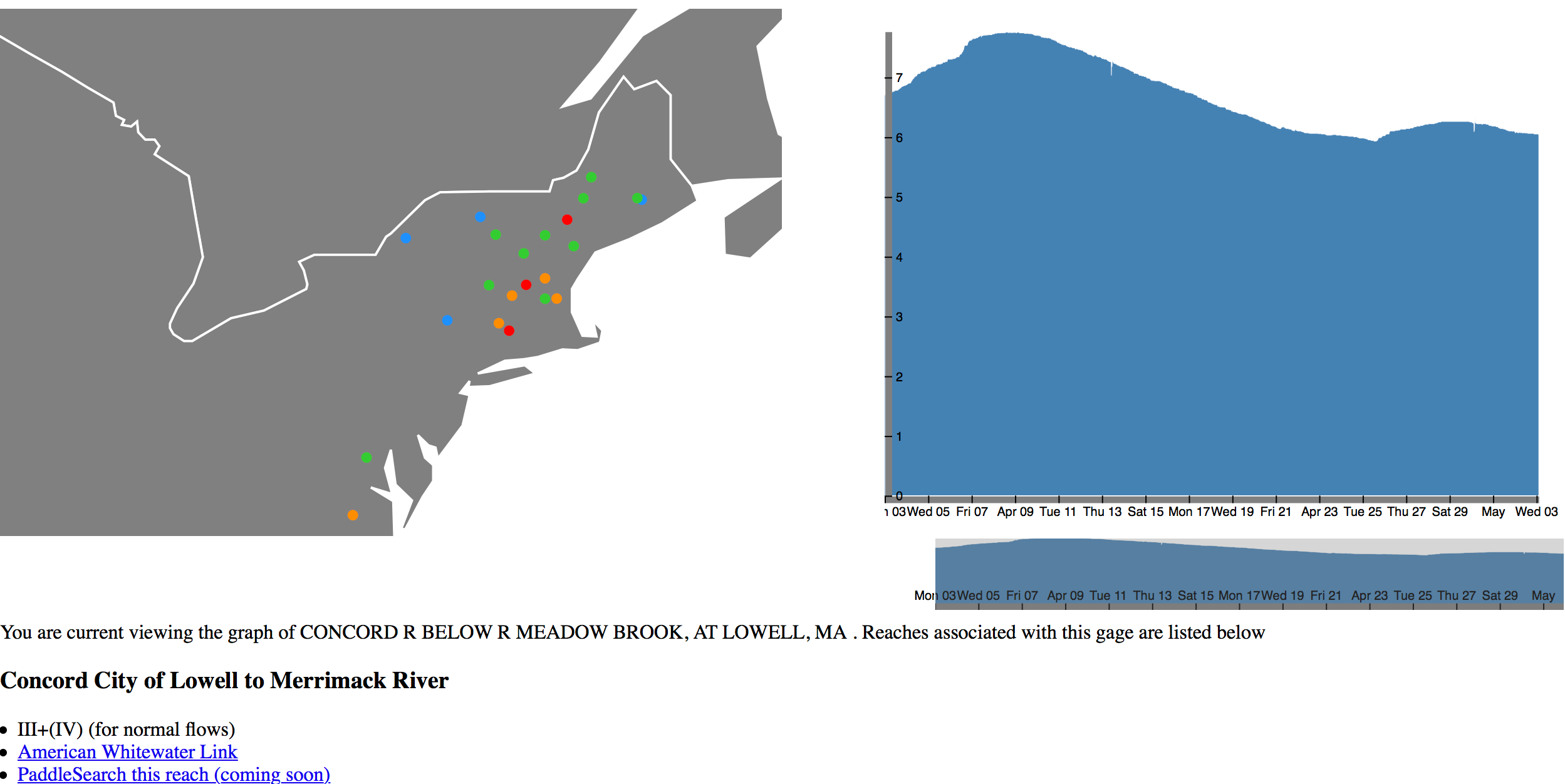
Flow Forecast Repository
Initially, a repository to forecast flash floods and stream flows, flow evolved to serve as a general time series forecasting libray. We are currently using flow forecast to forecast COVID cases around the U.S. as well as study transfer learning training on flow, wind, and solar data.
View Project
Game of Thrones chatbot
I developed a Game of Thrones chatbot from scratch using Flask, Redis, ElasticSearch, PostgreSQL, Spacy, and Tensorflow. The bot operated through a Flask based REST-API where incoming user messages (from the Slack-API) were combined with prior cached messages in Redis and fed to a combination of rule-based NLP methods and Tensorflow models. These methods in turn constructed queries to the appropiate data sources (ElasticSearch or PostgreSQL) and synthesized a response based on the returned information. Full conversation history for the bot was stored in PostgreSQL and periodically analyzed and reintegrated into the training data to improve performance. This app ran primarily on AWS (ElasticSearch service, ECS, and EC2), while a few of the Tensorflow components ran on GCP instances. Bot integrated with the Slack-API and used OAuth for authorization.
View Project
Peelout
This project aims to ease the difficulties surrounding utilzing deep learning models in a production environment. This involves three parts: creating a set of model agnostic tools to rapidly adapt models to the business use case, developing a set of scripts/extensions to existing frameworks to actually deploy the models, and designing a set of tools to monitor models and automatically adapt/continue to train the models. The focus now is on the deployment phase. Specifically, this consists of automatically packaging deep learning models into a Docker container and creating a Kubernetes based auto-scaling microservice that can integrate with other applications. There is also work to embed DL models in Flink (and other Java applications) directly with Java Embedded Python or JEP.
View ProjectDetecting and classifying conditions in medical imaging with limited annotated data
This research explored localizing and classifying a variety of conditions in lung X-Rays given only a small dataset through the use of transfer learning and meta-learning. I for the most part have abandoned this project to focus on my NLP research and developing Peelout.
View Project